

In Essay 1 we raised the floor by naming noise and mopping drift. In Essay 2 we tightened the loop with a small audit you can run on a Tuesday. This third piece turns the mirror: we test the question itself.
Here is the wager: if you ask the same case two ways and the goal, unit, horizon, constraints, or success metric shifts, the problem is the prompt, not the model. That is what we measure. UFI flags the flip. FCS checks whether the reasoning stayed on frame. Two numbers, low drama.
Methods can wait; first we ask the same thing twice. Then we run the tiny protocol: one case, two prompts, score UFI, score FCS, proceed. Floor, loop, mirror.
I write this as a vibe coder: I tune prompts, watch behavior, and let the audits do the counting. When the feel is off, UFI swings the hammer; when the logic is close, FCS calls the score. No cape, no theorem. Just repeatable checks.
The Question Behind the Question
You think you asked the model something clear. It answered fluently. You trust it.
But did it reflect what you meant to ask, or just the version you accidentally phrased?
Frame instability doesn’t just damage answers. It poisons comparisons. Once your framing shifts—your unit of analysis, your time horizon, your definition of success—you’re comparing ghosts. And ghosts don’t add up.
Here’s the real loss: drift hides in the places we don’t re-check. The earlier in the process it enters, the less likely we are to catch it.
In every prompt lives a wager: that the frame is steady enough to support a conclusion. This essay gives you the tool to check that bet.
This isn’t philosophy; it’s a measuring stick for slippery questions.
Note: the formal GTRF sketch sits right below this, where it belongs, with the translator’s note for readers who do not want symbols before coffee.
Unified Field as Audit Loop
The Unified Field is not a philosophy. It is a measurement protocol—a method for detecting, isolating, and reducing framing drift using structured model comparison and recursive logic. It is also a mirror: not just of outputs, but of the coherence and stability of the question itself.
At its core, the Unified Field method borrows from tensor-based recursive systems and reflects a principle found in the Enhanced GTRF cognitive architecture: that clarity is not achieved by more data, but by identifying resonance and drift across interconnected structures.
The GTRF Core: Recursive Coherence and Temporal Stability
GTRF—Generalized Tensor-Recursive Framework—is a meta-structure for modeling cognition across time. It organizes decision dynamics into three coupled tensors:
T_clear(t): emotional and cognitive stability
Ξ(t): logical coherence and recursion tracking
Π(t): strategic foresight and regret-minimizing policies
These tensors evolve through recursive time steps. The update function is:
dTt/dt = Rt(Tt, Λm)
Where:
Rt is a recursive operator,
Λm is a multiplicity constant that modulates how fast the system stabilizes or spirals,
and Tt is the full cognition state vector at time t.
Translator’s note: if tensors make your eyes cross, read this as “how we keep the question steady over time.”
GTRF isn’t just theoretical—it governs how systems maintain internal alignment when pushed through time. When C[Ξ(t)] = 0, logical coherence holds. When it rises, the system is wobbling. Unified Field builds on that: it applies this recursive pressure to prompts.
Okay, out of the lab—here’s the field test.
Unified Field as GTRF in Action
Instead of evolving cognition through full biological or social time, Unified Field compresses that recursion into prompt variants. It uses the LLM as a stable black box and tests the frame as the dynamic variable.
The prompts act as perturbations: slight semantic shifts. The responses act as output tensors. Your job is to compare the structure of the response tensors, not the words.
Think of each prompt-response pair as a frame-stability probe:
Prompt A → Response A → Frame vector F1
Prompt B → Response B → Frame vector F2
Then:
UFI = 1 if F1 ≠ F2
More precisely:
D_frame = ||F1 − F2|| → frame drift vector norm
Over time, you build a distribution of D_frame. This gives you not just binary flags but a continuous signal of prompt fragility.
“Figure 1 shows two frames from the same case asked two ways. F1 comes from Prompt A, F2 from Prompt B. D_frame is their distance at each step, with audit ticks at 3, 6, and 8.”
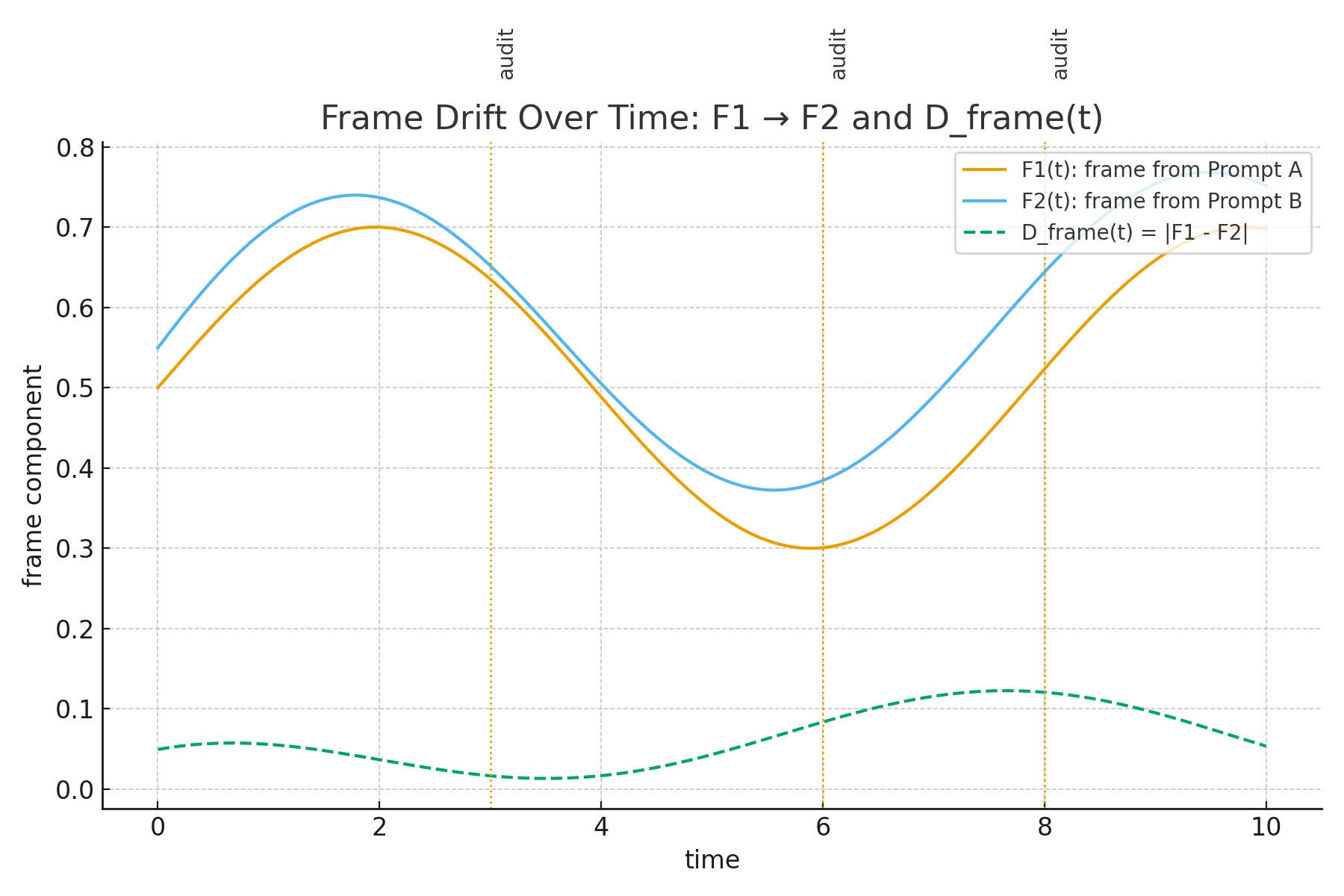
Figure 1. Frame drift over time for the same case asked two ways: F1(t), F2(t), and D_frame(t) = |F1 − F2|. Vertical lines mark audit checkpoints. If D_frame rises across two audits, freeze outputs, restate goal and metric verbatim, then rerun the pair. This is how a vibe coder works: feel first, then audit.
And just like GTRF uses recursive feedback loops to dampen emotional spikes or logic contradictions, Unified Field uses prompt iteration to stabilize framing logic. You’re regulating the volatility of the question structure, not just scoring outputs.
Fluent answers can hide wobbly frames; this is how you catch the wobble in time.
Why It Matters
This is the missing layer in most prompt engineering: time-based drift detection. What appears to be a minor linguistic shift might expose a major conceptual wobble. Without recursive checking, you can’t see it. But with GTRF logic embedded in Unified Field, you now can.
So while GTRF offers a formal architecture for cognitive-mode stability, Unified Field offers the applied method: a testable, teachable, business-runnable diagnostic loop to detect, not guess, where prompts lose coherence.
In short: GTRF is the engine. Unified Field is the wheel. Drive accordingly.
**If you like symbols, the formal sketch is below. If you work by feel, keep the protocol and skip the math.
Two numbers, low drama, high payoff: UFI and FCS.
Keep reading with a 7-day free trial
Subscribe to Wayne’s Substack to keep reading this post and get 7 days of free access to the full post archives.